
中国工程院院士,清华大学计算机科学与技术系教授 郑纬民
7月7日信息化百人会(ChinaInfo100,信百会)2024年度研讨会上,中国工程院院士、清华大学计算机科学与技术系教授郑纬民发表演讲。
郑纬民表示,AI 大模型正在从单模态向多模态发展,同时应用也很多,这使得算力爆发性增长,算力一直供不应求。但同时,相比英伟达,国产 AI 芯片系统生态不够好。
整体来看,大模型算力主要分为四个层次:模型研发、模型训练、模型精调、模型推理,因此,算力存在于大模型生命周期的每一环。
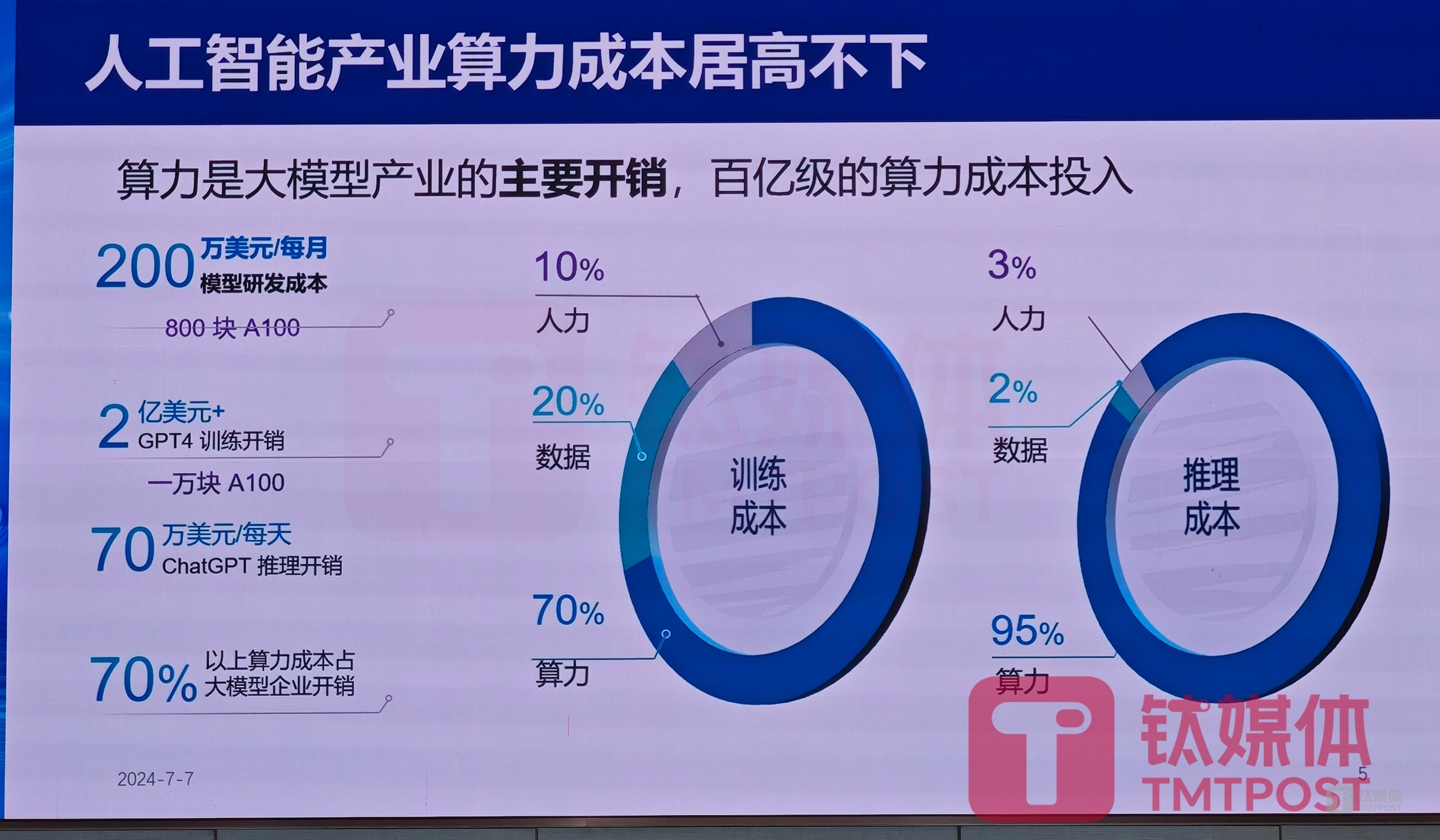
郑纬民提到,算力很贵,成本居高不下,如GPT-4用了800块英伟达A100,每月模型研发成本200万美元,其中,1万块A100的算力训练开销达2亿美元,ChatGPT每天推理开销达70万美元。而在大模型企业模型训练成本中,算力占70%,而在模型推理成本中,95%都是算力。
其中,大模型训练层面,郑纬民指出,目前有三种支持系统:
第一个是基于英伟达芯片的GPU系统。硬件性能好,编程生态好,但是不卖给中国,一卡难求,价格也贵了很多倍。
第二个是基于国产AI芯片的系统。
“这些年国产芯片无论是软件硬件都有很大的进展,但是用户不太喜欢用,原因是国产卡的生态系统不太好。”
郑纬民早前在2024世界人工智能大会一场分论坛上详细阐述称,尽管国内包括上海天数智芯、沐曦MetaX等国内20多家公司在生产AI芯片,芯片做的还是很不错的,进步也很大。但问题在于,国内 AI 系统时间短,特别是软件系统方面还不够成熟。
什么是生态系统好呢?郑纬民给出的定义是,如果原来用英伟达写了一个AI CUDA软件,现在很容易移植到国产系统上,写起来的方法跟原来差不多,就叫生态好。如果移植起来,没有一年两年移不过来,那就是不好。
“现在我们的状况就是生态不太好,所以大家不喜欢用。”郑纬民认为,这需要做好系统设计和相关软件优化,具体包括十个方面:编程框架、并行加速、通信库、算子库、AI编译器、编程语音、调度器、内存分配系统、容错系统、存储系统等。
他表示,生产AI芯片的厂家,一定要把这个十个方面做好,做好了大家就喜欢用。在郑纬民看来,在国产算力支撑大模型训练时,国产AI芯片只要达到国外芯片60%的性能,但如果把前述十个方面的软件生态新做好了,客户也会满意会用。
“大多数任务不会因为芯片性能只有60%而有明显感知,大家感觉到的不好用还是生态不行。即使你做的硬件性能是人家的120%,但如果这十个软件没做好,还是不会用。”郑纬民说。
第三种是基于超级计算机的系统。目前国内14个国家级超算中心,但机器空置率较高,用得不是非常满。
那么,用超级计算来做大模型训练行不行?郑纬民认为可以,但需要进行软硬件协同设计,并有望节省训练成本。现场以Llama-7B和百川大模型的演示显示,使用国产超级计算训练,相较英伟达集群可节省成本82%左右。
除了算力,存储也存在于大模型的生命周期的每一环,包括数据获取、数据预处理、模型训练、模型推理等。郑纬民强调,内存对 AI 推理特别重要,如果改进存储系统,性能能有好几倍的提高,这意味着可以少买很多卡。
郑纬民指出,国产芯片在设计层面不能一味追寻提升大模型训练多用的半精度(FP16)浮点计算性能,而应注重半精度和双精度(FP64)浮点计算性能的平衡,两者算力之比应为100:1,这样才能适应更广泛的AI算法。此外,大模型任务训练量大、往往需要多卡互联,芯片层的网络参数、体系结构、存储性能愈发成为关键。
他认为,国产 AI 芯片亟待解决网络平衡设计、I/O子系统平衡设计、做好内存设计等技术能力。
近年来,包括了天数智芯、沐曦、摩尔线程、百度昆仑芯等一众GPU创业公司发布新产品并投入量产,但由于软件生态等原因,采购仍未起量,生态构建亟待加强。而同时,据第一财经报道,尽管性能大幅下降,英伟达有望未来几个月内在中国交付超过100万颗“中国特供版”H20芯片,今年整体在中国销售 AI 芯片总额达到约120亿美元,而这些芯片不受美国对华 AI 芯片出口管制,每颗H20芯片价格则为1.2万-1.3万美金之间。
“如果把大模型基础设施平衡设计这些方面做好,别人用1万张卡,我们用9000张卡就可以了。如果这个事情不考虑,乱做一通,人家1万块卡,你可能得3万块卡才能达到(类似)效果。”郑纬民在演讲结尾表示。
(作者|林志佳,编辑|胡润峰)